1 验证环境
1.1 本次验证硬件配置
|
类型 |
型号 |
硬件配置 |
|
服务器 |
2U2路服务器 |
CPU:Intel(R) Xeon(R) Gold 5318Y CPU @ 2.10GHz |
|
内存:12*16GB |
||
|
存储控制器:支持RAID 1(系统盘) |
||
|
硬盘 |
系统盘 |
2*480GB SATA |
|
数据盘 |
4*3.84T NVMe SSD(忆联UH711a) |
|
|
网卡 |
网卡 |
网卡:2*2端口10GE以太网卡 1*4端口千兆以太网卡 |
|
交换机 |
10GE交换机 |
48端口10GE交换机 |
|
注:实验室使用3台服务器,每台分4块数据盘,用户可根据实际盘的数量需求进行配置(目前只支持512B扇区的NVMe盘) |
||
1.2 本次验证软件配置
|
类型 |
型号 |
版本 |
|
存储软件 |
H3C UIS超融合管理平台 |
V7.0 (E0750P10) |
|
FIO |
IO测试 |
3.18 |
|
SAR |
网络监控 |
10.1.5 |
|
IOSTAT |
盘侧IO统计 |
10.0.0 |
|
MPSTAT |
CPU利用 |
10.1.5 |
1.3 本次验证测试环境规划
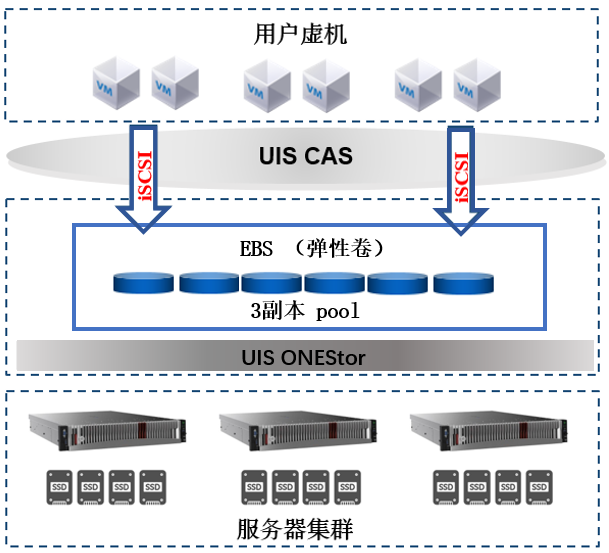
图2:测试环境规划架构图
2 验证方法
步骤1:块存储测试的存储配置为存储池采用3副本,配置6个虚拟机客户端。在默认数据池(default Data Pool)创建6个大小为100GB的块设备,并添加到iSCSI网络存储池中,虚拟机添加iSCSI网络存储池中的块设备后进行IO测试。
步骤2:发IO测试前,需对服务端和客户端的IO、CPU、网络进行监控,每2秒采集一次数据,各对应如下命令:
# iostat -xmt 2 >> iostat.log &
# mpstat -P ALL 2 >> mpstat.log &
# sar -n DEV 2 >>sar.log &
步骤3:在各测试客户端上运行fio任务后台监听服务,然后同时对6个块设备下发IO(选取其中一个客户端执行下发IO操作)。正式测试前需要对各块设备进行预写。fio参考命令如下:
# fio --server & //各客户端开启后台监听服务
# fio --client=host.list fio.job //各客户端下发IO
步骤4:步骤3完成后,汇总所有客户端fio的BW、IOPS、平均时延。
3 验证结果
本次在H3C UIS块存储场景下的验证结果如下:
3.1忆联UH711a在4KB随机读写下的表现
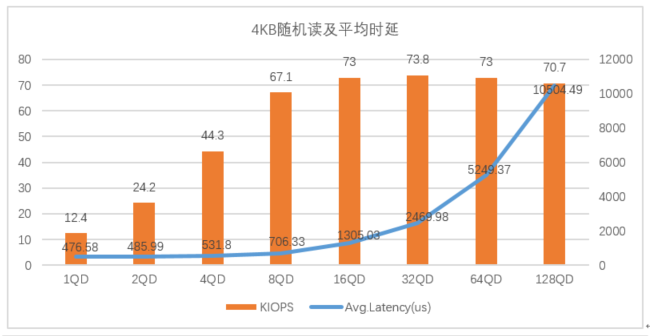
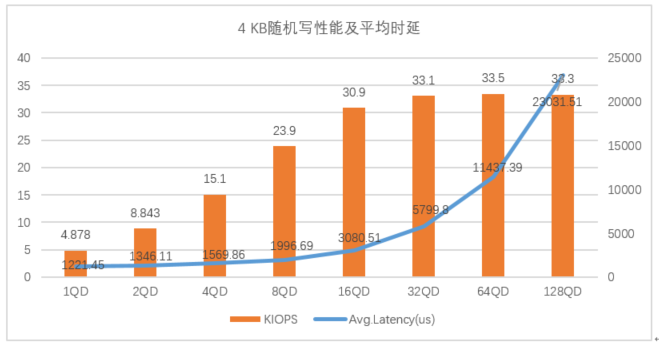
图3:忆联UH711a在4K随机读写下的表现
从图3可以看出,在4KB随机读写场景下,当队列深度在1-32QD时,UH711a的IOPS呈增长趋势,平均时延增长幅度较小,整体表现较好;当队列深度大于32QD时,IOPS增长较少,平均时延增长幅度较大。
由此可见,在4KB随机读写场景下,UH711a可为32QD及以下场景提供高性能、低时延的存储服务。
3.2忆联UH711a在4 KB随机7:3混合读写下的表现
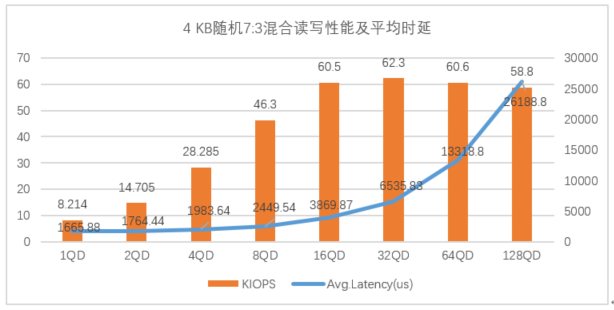
图4:忆联UH711a在4KB随机7:3混合读写下的表现
如图4所示,UH711a在4KB随机7:3混合读写性能场景下,在32QD及以下展现优势,IOPS峰值在32QD,可达62.3K,对应平均时延为6535.83 us(6.5ms )。当队列深度大于32QD时,IOPS呈下降趋势,平均时延显著增加。
在此场景下,UH711a为32QD及以下场景提供最佳存储性能。
3.3忆联UH711a在128 KB顺序读写下的表现
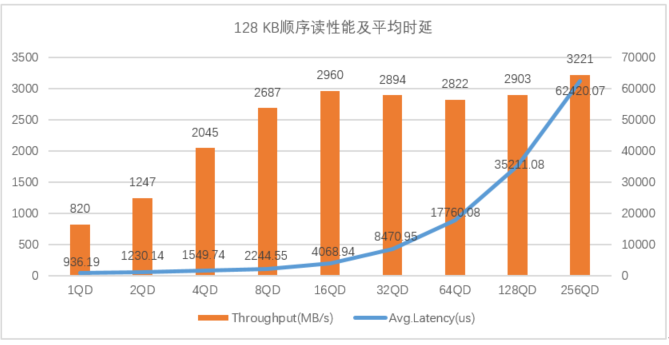
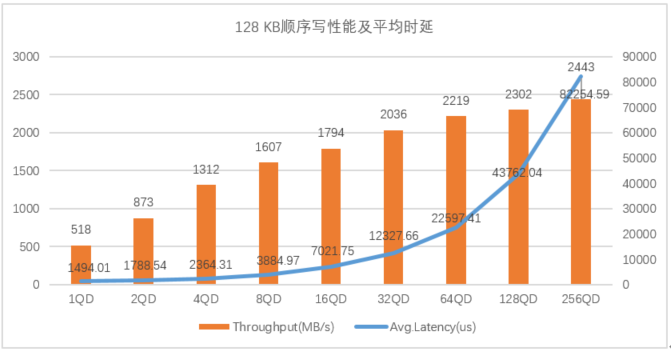
图5:忆联 UH711a 在128 KB顺序读写下的表现
图5展示了UH711a在128KB顺序读场景下,队列深度在1到16QD时,UH711a读带宽呈线性增长趋势,平均时延增长幅度较小;当队列深度大于32QD时,读带宽下降,平均时延增长幅度较大。在128KB顺序写场景下,UH711a写带宽随着队列深度的增加而不断提升,平均时延在1-32QD表现较好。
以上数据趋势验证了在128KB顺序读写中32QD及以下场景UH711a的整体性能表现更为突出。
地址:深圳市南山区记忆科技后海中心B座19楼
电话:0755-2681 3300
邮箱:support@unionmem.com