日期:2026-01-30 浏览:6289
分享:



为应对AI大模型时代多元化的存储挑战与存算分离部署需求,英特尔与忆联基于既有合作成果,再度深化协同创新。依托RDMA与NVMe硬件技术,结合SPDK高性能存储服务,重磅推出企业级网络存储解决方案白皮书,旨在充分发挥至强®6处理器与忆联UH812a企业级SSD的性能潜力,全面满足AI训练与推理场景下的高吞吐、高带宽及极致低延迟需求。

RDMA与NVMe是构建AI时代高性能存算分离架构的两大基石,二者通过突破传统I/O瓶颈,显著提升了AI训练与推理的整体效率。
超低数据传输延迟:RDMA可实现微秒级的低延迟传输,配合NVMe协议,协同确保GPU与CPU计算单元持续满载,避免因数据等待造成的算力闲置。
海量数据吞吐支撑:AI训练需处理EB级非结构化数据。单块PCIe Gen5 NVMe SSD可提供超过14GB/s的顺序读取带宽,结合RDMA网络对多节点并发读写的支持,共同满足TB/s级别的连续读写需求。
多模态工作流适配:AI任务常需并行处理多种接口数据。NVMe提供了统一的低延迟、高并发访问层,而RDMA则保障了跨节点的数据一致性,支持混合架构无缝衔接。
软硬件深度协同:结合优化的SPDK软件技术、充分释放CPU存储平台、企业存储SSD及RDMA网卡的性能潜力,实现系统整体效能最大化。
“忆联UH812a PCIe 5.0企业级固态硬盘采用自研主控,支持NVMe 2.0协议和双端口设计,顺序读写速度高达14900/10500 MB/s,4K随机读写性能达3500K/1000K IOPS。其独创的LDPC+DSP算法引擎将闪存寿命提升5倍,同时通过动态功耗调节技术实现全场景能效优化,顺序读最大运行功耗在18W以内,待机功耗≤5W,满足AI训练、金融交易等场景的差异化需求。通过英特尔BKC认证及中子辐照测试,MTBF超过250万小时,年失效率低于0.35%,在各种严苛环境中展现出卓越稳定性。”
企业存储产品线总裁 蒋毅
深圳忆联信息系统有限公司
作为忆联旗下首款PCIe Gen5 企业级SSD,UH812a/UH832a面向数据中心混合业务、云计算及AI等高负载应用场景,提供高带宽、低延迟的存储解决方案,以全生命周期稳态性能为千行百业数字化转型提供坚实支撑。
性能全面提升
相较于上一代产品UH811a/UH831a,UH812a/UH832a的数据吞吐效率提升至2倍,顺序读写带宽高达14900 MB/s,随机读写性能高达3500K IOPS,能够为AI训练与推理任务提供强劲的性能保障。
容量灵活覆盖
UH812a/UH832a提供1.6TB至15.36TB的多种容量选择,可满足大规模数据中心混合业务及云端海量存储需求,为多样化业务场景提供弹性扩展能力。
时延显著优化
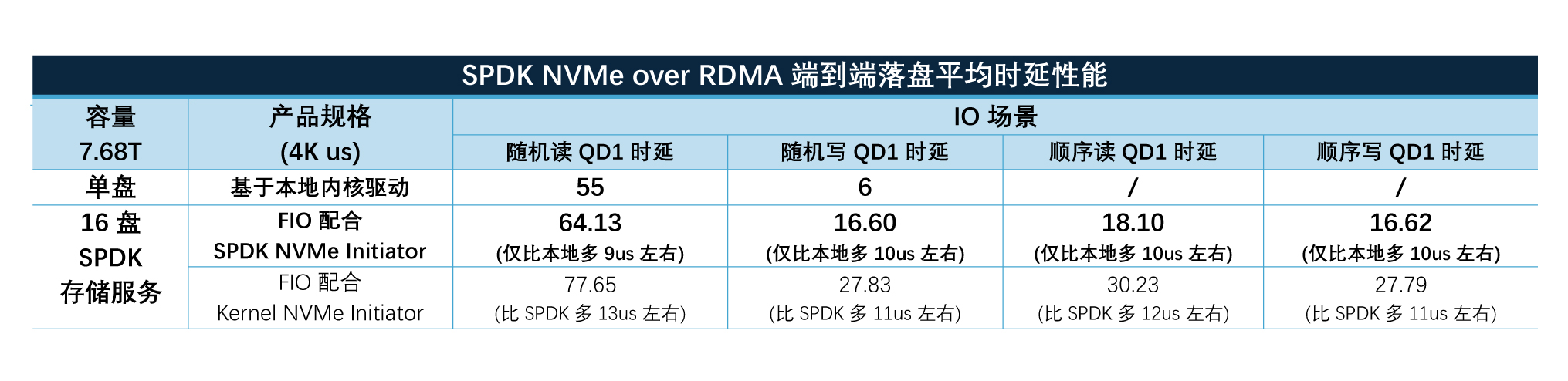
忆联通过在主控芯片与NAND介质上的技术创新,将UH812a/UH832a的读写延迟降低至55 / 6 μs,整盘时延较上一代下降约30%。这一优势在数据密集型应用中表现尤为突出,不仅可缩短AI训练与推理时间,更能提升AI系统与应用的整体运行效率。
“凭借创新的模块化x86架构,英特尔® 至强® 6处理器家族为特定需求以及跨私有云、公有云和混合云的工作负载配置和部署专属基础设施。为提供更高灵活性,英特尔® 至强® 6处理器采用两种不同的CPU微架构:性能核(P-core)和能效核(E-core)。随着最新产品的发布,完整的英特尔® 至强® 6处理器家族现已全面上市,涵盖了多种专为满足多样化业务需求而打造的处理器选择。无论是高密度计算与横向扩展工作负载,还是AI和HPC加速的高密度多核计算,亦或是满足不同需求的各种存储场景,都能更轻松地应对。”
生态业务拓展总监 徐冉
英特尔中国数据中心和人工智能集团
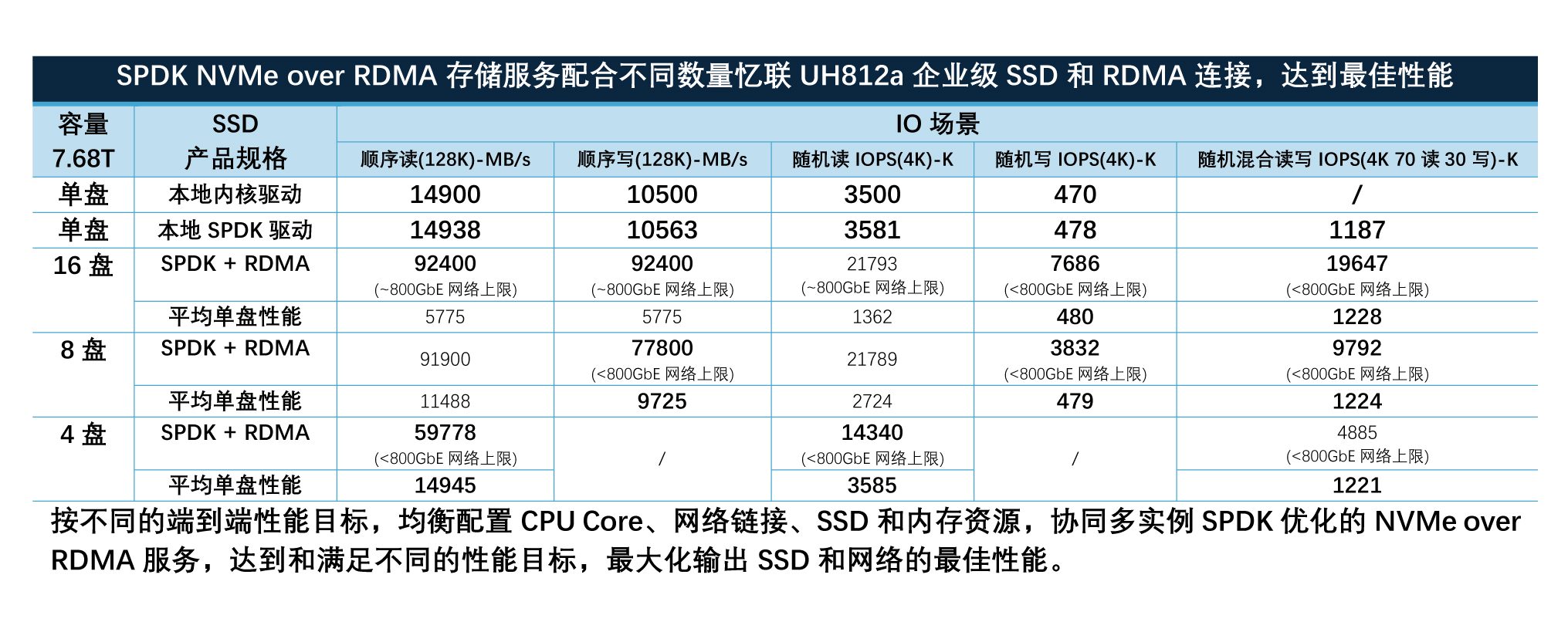
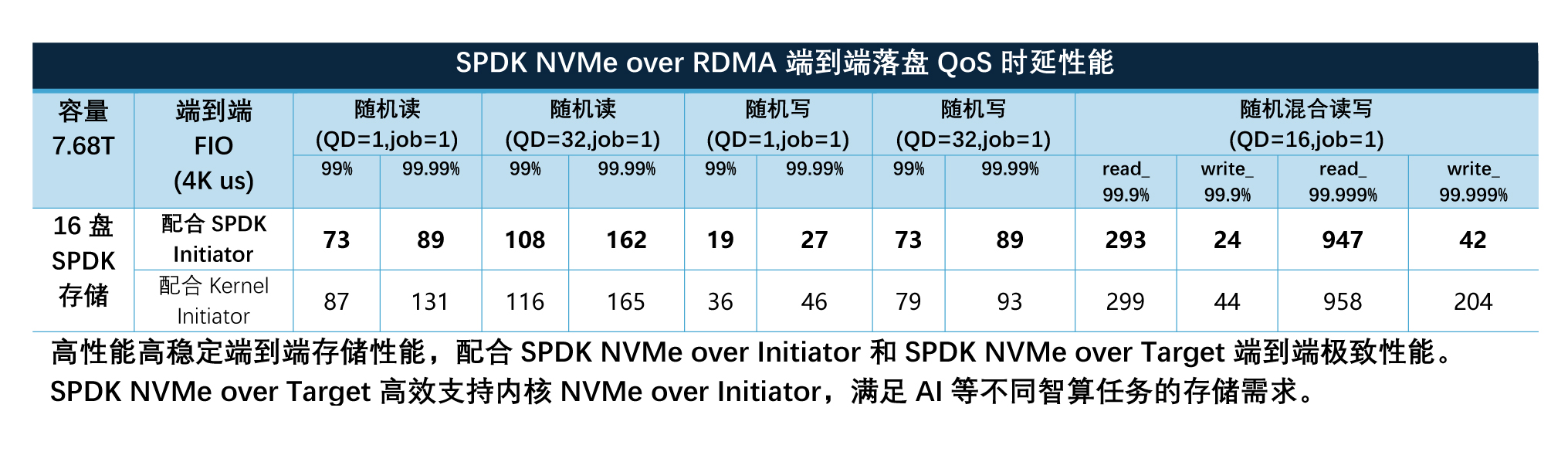
以典型2路至强® 6 处理器,16盘7.68TB PCIe Gen5 NVMe SSD和4x 200GbE RDMA网卡为例,在高性能计算节点侧高性能输出:
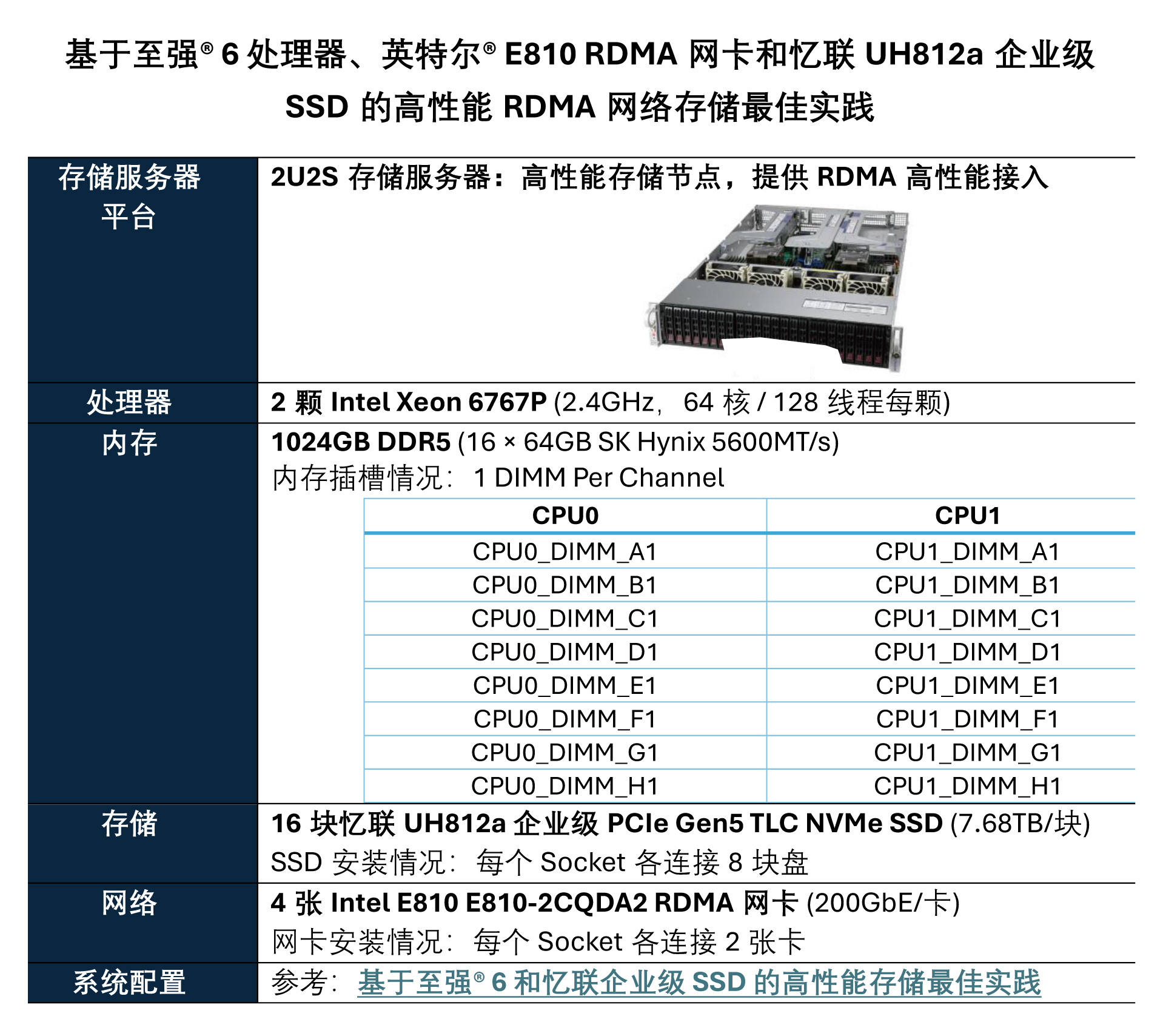

企业级网络存储最佳实践得益于:
• 至强® 6 处理器的硬件提升
• 硬件平台以及SSD和内存优化配置
• 忆联UH812a PCIe 5.0 SSD的提升
• BIOS等固件的优化设置
• 英特尔® E810 200GbE RDMA网卡的提升
• SPDK驱动和RDMA存储服务的软件优化
企业级网络存储最佳实践收益:
• 全面满足AI等各类智算任务对高性能、高扩展存储的需求。
• 通过软硬件资源的协同与优化,最大化释放存储平台性能潜力。
未来,英特尔与忆联将持续深化合作,围绕AI等前沿领域探索更多存储最佳实践。我们致力于为企业用户提供更稳定、可靠且高性能的存储解决方案,助力其在复杂场景中实现高效部署,充分释放数据潜能,驱动业务创新与增长。

地址:深圳市南山区记忆科技后海中心B座19楼
电话:0755-2681 3300
邮箱:support@unionmem.com